今回は「GoogleドライブでOCRした後のチェックポイント」に関して書いていきます。
GoogleドライブのOCR機能が便利で、主に読書感想を書く際に本から引用する部分をOCRしています。
かなり高精度で文字を読み取ってくれます。
ただ、OCRの読み取り精度が100%とまではいきません。
自分の体感としては、90~95%くらいの読み取り精度です。
この90~95%を100%まで持っていくために、目視でチェックしています。
この目視チェックを繰り返していくうちに、OCRの読み取りが苦手なところを概ね掴めてきました。
どういった目視チェックをしているか、OCRの読み取りが苦手なところはどこか。
今回の記事ではその辺りに関して書いていきます。
OCRとは?
まずは「OCR」の概要をざっくり書いておきます。

チェック①:数字
ということで、ここから目視チェックのポイントを書いていきます。
まずは「数字」です。
OCRは数字の読み取りが苦手なようです。
例えば、「2024年」という文字をOCRで読み取った時に「224年」になったりします。
他にも「334」が「34」になったり、「83.5%」が「8・5%」になったりします。
「0~9」のうち、どの数字が苦手か。
そこまでの傾向は掴めてませんが、とにかく数字が正しく読み取れないことが割とあります。
数字の読み取りがうまくいかないのは、ひらがなや漢字よりも致命的な気がします。
「83.5%」が「8・5%」では、まるで違うデータになってしまいます。
この辺りは慎重に目視チェックしています。
チェック②:改行
次は「改行」です。
本では改行されているところが、OCR後では改行されないことがあります。
本来改行されるところで改行されないため、文章が続いて読み取られます。
改行のある/なしは内容自体に影響はないので、そのままコピペしても良いのかもしれません。
ですが、本の内容をなるべく忠実に引用したい気持ちがあるため改行のチェックも欠かせません。
チェック③:特殊な段組み
次は「特殊な段組み」です。
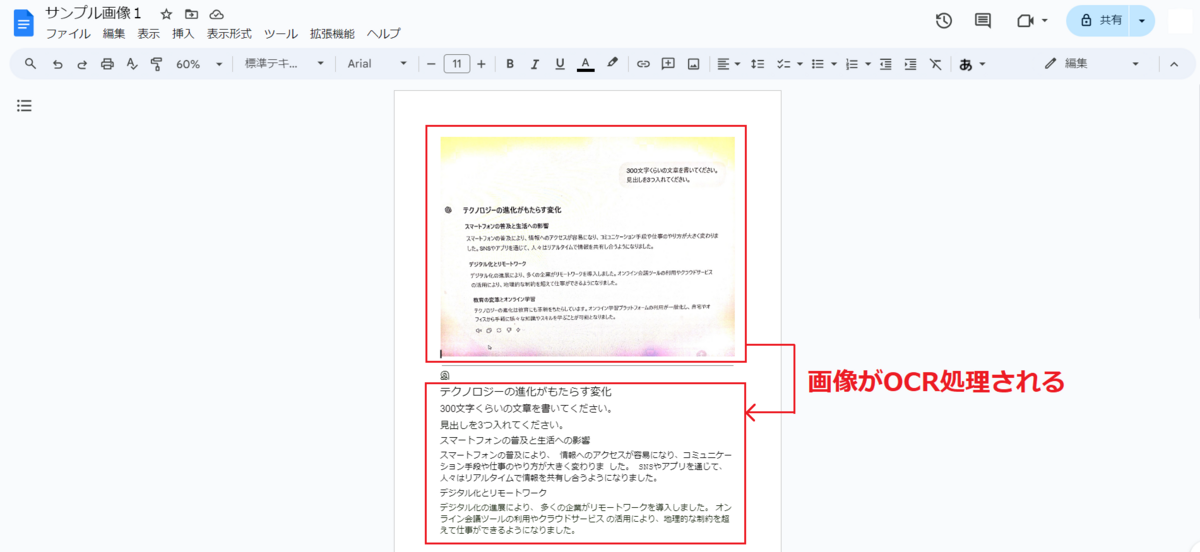
本を読んでいると、たまに特殊な段組みが登場します。
ページの上部にイラストやグラフ、下部に文章が配置されているものです。
こういった段組みをOCRするのは苦手なようです。
上部のイラストやグラフに文章が含まれる場合、それも読み取ってしまいます。
それが下部の文章と干渉してしまうようです。
結果として、文章の順序がバラバラに読み取られることがあります。
下部の文章自体は読み取られるのですが、上部の文章と混在してしまうことが多いです。
こうなってくると、上部の文章を取り除くのが面倒です。
対策案は3つあります。
対策案①:上部の文章を取り除く
文字認識自体はうまくいっているため、上部の文章を取り除いていきます。
ただ、上部と下部の文章が混在しているためメチャクチャな文章になっています。
取り除く作業は妙にストレスです。
対策案②:手入力する
そもそも引用に必要なのはページ下部の文章だけです。
上部はイラストやグラフですし、下部だけなら文量は少なめです。
取り除く作業は妙にストレスなので、ここだけ手入力してしまいます。
対策案③:上部のイラストやグラフを隠す
OCRするにあたっては、上部のイラストやグラフは不要です。
なのでその部分を画像加工して隠してしまいます。
そうすることでOCRが変に認識しなくなり、問題なく文章が読み取れます。
私は「対策案②:手入力」が多いです。
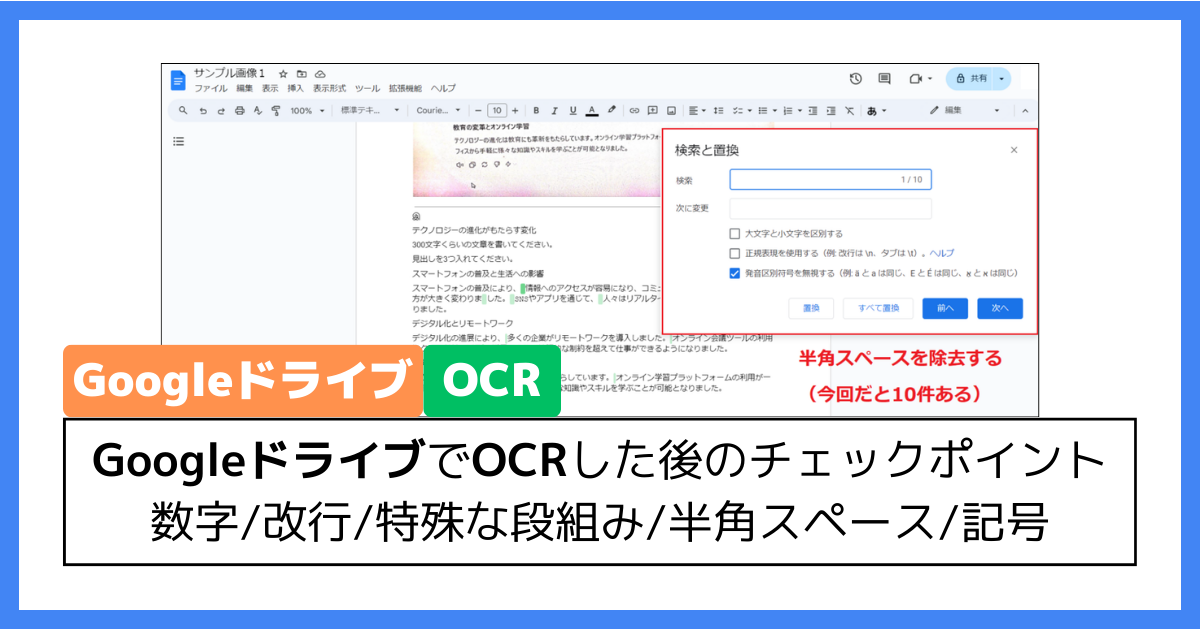
チェック④:半角スペースや記号
次は「半角スペースや記号」です。
OCRされた文章は、半角スペースが入り込んでしまうことが多いです。
以下画像のような感じです。

半角スペースは余計なので除去する必要があります。
あと「!」「?」「=」「~」あたりの記号が半角で読み取られてしまいます。
個人的に、この辺りは全角にしたいところ。
これらを今はGASで自動置換しています。
詳細は以下記事に書いています。こちらも良ければぜひ。
以下のルールで置換しています。
| 置換前 | 置換後 |
| 半角スペース | 除去 |
| ! | ! |
| ? | ? |
| ( | ( |
| ) | ) |
| = | = |
| ~ | ~ |
プログラムを抜粋すると、以下の通りです。
let replaceText = body.getText().replaceAll(" ", ""); replaceText = replaceText.replaceAll("?", "?"); replaceText = replaceText.replaceAll("!", "!"); replaceText = replaceText.replaceAll("(", "("); replaceText = replaceText.replaceAll(")", ")"); replaceText = replaceText.replaceAll("=", "="); replaceText = replaceText.replaceAll("~", "~"); body.setText(replaceText);
おわりに
ということで、「GoogleドライブでOCRした後のチェックポイント」に関してアレコレ書いてみました。
GoogleドライブのOCR機能を知る前は、本から引用する部分を全て手入力していました。
これがかなり地道で大変な作業でした。
OCR機能を知ってからは、かなり作業が軽減しました。
GASで自動化できた部分もあって、さらに作業が軽減しました。
最後の目視チェックは面倒ではありますが、当初の全て手入力の状態と比べると劇的な変化です。
この記事が参考になれば幸いです。
関連記事
GAS(Google Apps Script)に関してはいくつか記事にしています。
気になる記事があればぜひ。
GASの活用事例
GASを活用してGoogle DriveでのOCR処理を効率化 - 派生記事